[Backend] Elasticsearch

데이터의 바다에서
엄청나게 방대한 유저 정보와 같은 데이터가 있다고 해보자,여기서 "Kim" 이라는 이름으로 시작하는 모든 데이터를 RDB에서 조회하려면 모든 행을 검사하며 "Kim"이 포함되어 있는지를 확인해야한다.이런 작업은 막대한 부하를 줄 수 있고 데이터가 많아질수록 비효율적으로 변한다.
일래스틱...서치?
오픈소스 검색,분석엔진으로 대량의 데이터를 저장하고 분석하고 조회하는데 특화되있다.RESTful API를 통해 동작하며 대규모 데이터 처리에 특화되어 다양한 설정과 데이터 조작을 제공한다.
역색인 구조
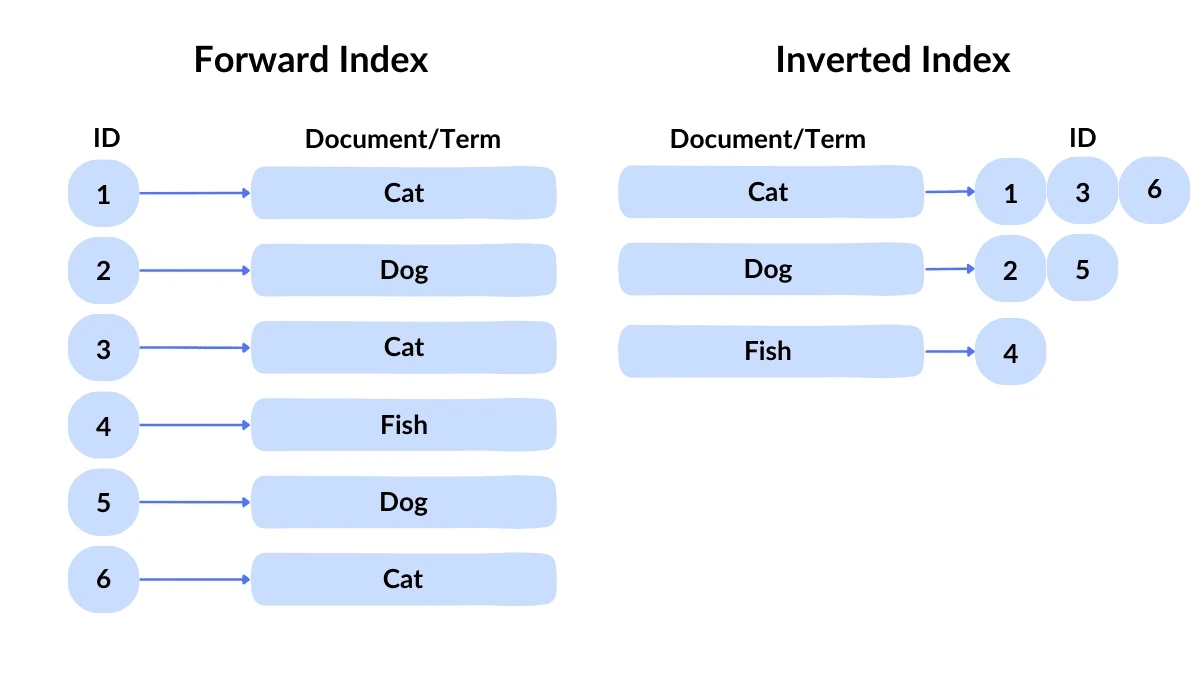
책에서 무언갈 찾을 때 우린 책 맨 뒷장을 펼쳐 색인을 뒤져본다.예를 들어 위 이미지에서 "Cat"을 찾으려면 1,3,6을 조회하면 되는 것이다.이처럼 키워드를 통하여 찾아내는 방식을 역색인 구조라 한다.
특징
1.분산/확장성/병렬처리
Elasticsearch 구성 시 보통 3개 이상의 노드(Elasticsearch 서버)를 클러스터로 구성하며, 데이터를 샤드(Shard)로 저장 시 클러스터 내 다른 호스트에 복사본(Replica)을 저장해 놓기 때문에 하나의 노드가 죽거나 샤드가 깨져도 복제되어 있는 다른 샤드를 활용하기 때문에 데이터의 안정성을 보장한다.
또한 데이터의 분산과 병렬처리가 되므로 실시간 검색 및 분석을 할 수 있고, 노드(Elasticsearch 서버)를 수평적으로 늘릴 수 있게 설계되어 있기 때문에 노드를 클러스터에 추가할 수 있다.
2.고가용성
동작 중 죽은 노드를 감지하고 삭제하며 데이터의 안전한 접근을 보장한다
3.멀티테넌시(Multitenancy)
여러개의 인덱스를 저장하거나 관리하고 하나의 쿼리나 그룹 쿼리로 여러 인덱스 데이터를 검색할 수 있다
구조
Document
데이터의 최소 단위로 JSON 객체 하나를 의미한다.하나의 Document에는 다양한 Field가 있으며 중첩구조를 지원하며 Document안에 Document도 지원한다.
Type
여러개의 Document가 모여서 한개의 Type를 이룬다.
Elasticsearch 7.0부터는 Type이 완전히 사라졌으며 Index가 그 역할을 대신함
Field
Field는 Document에 들어가는 데이터 타입으로 RDBMS의 Column과 비슷하다.하지만 Elasticsearch의 필드는 RDBMS보다 동적이다.RDBMS에서는 하나의 Column이 하나의 데이터 타입만 가질 수 있지만,Elasticsearch에서는 하나의 필드(Field)가 여러개의 데이터 타입을 가질 수 있다.
Index
여러개의 Type이 모여 한개의 Index를 이룬다.RDBMS는 쿼리 하나로 여러 데이터베이스의 데이터를 동시에 조회할 수 없지만,Elasticsearch는 가능한다.Elasticsearch를 분산환경으로 구성했을 경우 Index는 여러 노드에 분산 저장/관리된다.기본설정은 5개의 Prmiary Shard와 1개의 Replica Shard를 생성한다. 샤드 수는 인덱스 생성 시 옵션 값을 이용하여 변경 가능함.
Spring에서의 구현
1. Elasticsearch를 관련 의존성 추가
implementation("org.springframework.boot:spring-boot-starter-data-elasticsearch")2.Elasticsearch 연결 설정 클래스 추가
@Configuration
@EnableElasticsearchRepositories(basePackages = ["org.springframework.data.elasticsearch.repository"])
class ElasticsearchConfig : ElasticsearchConfiguration() {
override fun clientConfiguration(): ClientConfiguration {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build()
}
}3.Entity 작성
@Document(indexName = "item")
@Mapping(mappingPath = "static/elastic-mapping.json")
@Setting(settingPath = "static/elastic-token.json")
data class ItemDocument(
@Id
@Field(name = "id", type = FieldType.Keyword)
val itemId: String,
@Field(type = FieldType.Keyword)
val user: String,
@Field(type = FieldType.Text)
val name: String,
@Field(type = FieldType.Text)
val description: String,
@Field(type = FieldType.Text)
val category: String,
@Field(type = FieldType.Integer)
val price: Int,
@Field(type = FieldType.Text)
val itemImage: String
)- @Document를 통해 Elasticsearch의 "item" 인덱스에 매핑한다
- @Mapping, @Setting 를 통해 클래스에 해당하는 매핑/세팅 정보를 json파일에서 가져온다
4.Repository 작성
interface ItemSearchRepository : ElasticsearchRepository<ItemDocument, Long> {
fun findByName(keyword: String): List<ItemDocument>
}5.Service 작성
@Service
class ItemSearchService(private val itemSearchRepository: ItemSearchRepository) {
fun createItem(itemDocument: ItemDocument): ItemDocument {
return itemSearchRepository.save(itemDocument)
}
fun getItemByName(keyword: String): List<ItemDocument> {
return itemSearchRepository.findByName(keyword)
}
}6.Controller 구현
@RestController
@RequestMapping("/search")
class ItemSearchController(private val itemSearchService: ItemSearchService) {
@GetMapping
fun search(@RequestParam("keyword") keyword: String): ApiResponse<List<ItemDocument>> {
return ApiResponse.onSuccess(itemSearchService.getItemByName(keyword))
}
@PostMapping
fun create(@RequestBody itemDocument: ItemDocument): ApiResponse<ItemDocument> {
return ApiResponse.onSuccess(itemSearchService.createItem(itemDocument))
}
}